自动驾驶的算力革命,英伟达对阵特斯拉,谁会

自动驾驶技术,环境感知是其关键,神经网络算法则是核心。随着自动驾驶技术的大面积落地,传统的通用处理器已不能很好地满足需求,于是专门面向自动驾驶领域的处理器应运而生。
推荐阅读:自动驾驶
那么,这些专用处理器与传统的通用处理器相比有着怎样的优势?不同自动驾驶专用处理器之间又有着怎样的差异?今天我们就以特斯拉/英伟达所推出的产品为例为大家解答。
自动驾驶算法的特殊需求
在之前的文章中我们提到,当今自动驾驶领域所运用的视觉识别算法,基本上都基于卷积神经网络的概念,视觉算法的运算本质上是一次次的卷积运算。
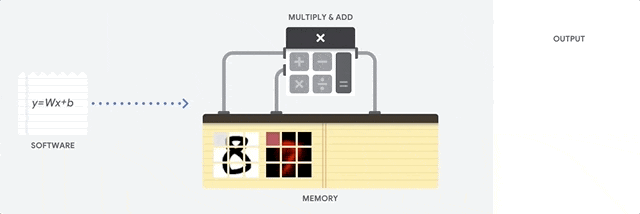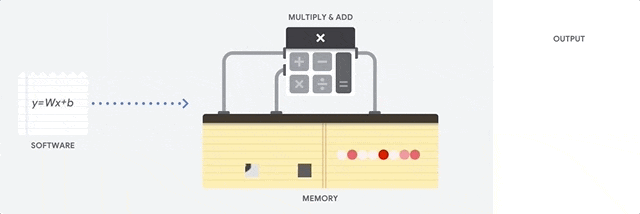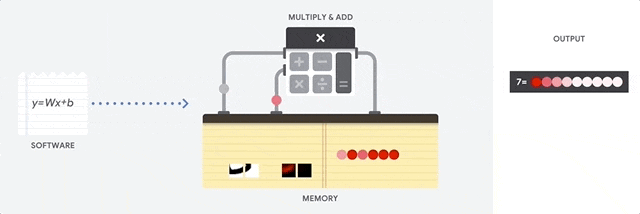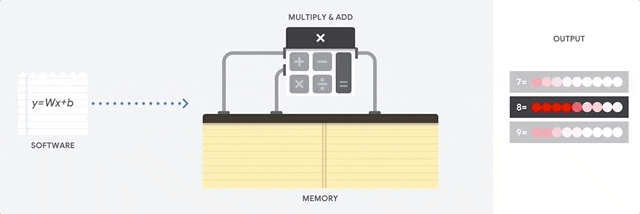

这种计算并不复杂,本质上只涉及到加减乘除,也就是一种乘积累加运算。但这种简单运算在卷积神经网络中是大量存在的,这就对处理器的性能提出了很高的要求。
以ResNet-152为例,这是一个152层的卷积神经网络,它处理一张224*224大小的图像所需的计算量大约是226亿次,如果这个网络要处理一个1080P的30帧的摄像头,他所需要的算力则高达每秒33万亿次,十分庞大。
那么,如何提高乘积累加运算的效率,就是提高自动驾驶处理器性能的关键。
并行计算脱颖而出
通用处理器(CPU)的架构,旨在可以快速地执行任何可以计算的计算,同时保持很高的速度,属于串行计算。这就导致了CPU当中的单个运算单元性能强大,但结构复杂,每个处理器中通常只能容纳数量有限的运算单元。
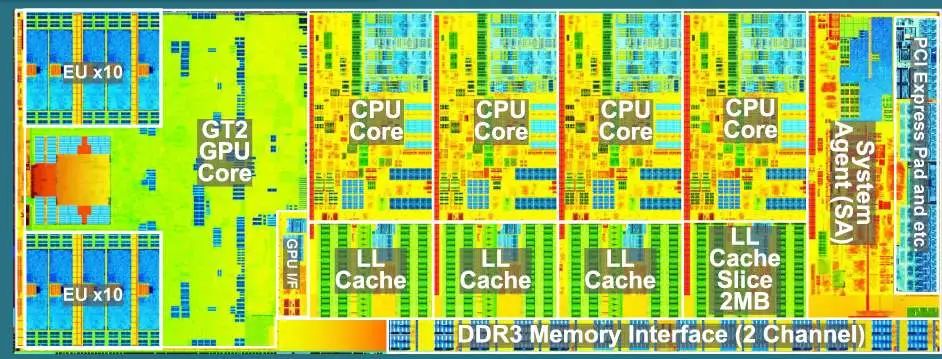
CPU架构示例,可见运算核心只有四个,但每个占用面积都很大。
以曾经的旗舰级CPU i7-9700k为例(非上图),其拥有8个核心,单个核心的运算频率可以达到4.9GHz,也就是每秒49亿次,整个处理器的算力就是8*4.9GHz=39.2GOPS。这个算力对于ResNet-152网络来说,每秒只能处理不到两张224*224大小的图像,没有实际应用的意义。
而图形处理器GPU则不同,它内部的计算单元是非常多的小核心,这些核心单个性能不及CPU,只能进行简单运算,但由于数量多可以同时进行非常多的运算,属于并行计算。推荐阅读:自动驾驶